Anonymization is achieved by deleting or blanking (nulling) all direct and indirect personal identifier fields.
Figure 1. Example Of Nulling Anonymization
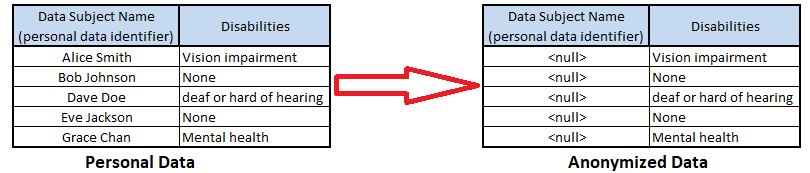
- Pros: There is little risk of de-anonymization (the process being reversed engineered back into personal data.
- Cons: The loss of the dataset structure can be issued for developers seeking to create test datasets from production data, as null or blanked data fields significantly hinders application testing capabilities, and can cause application errors.
Anonymization is achieved by overwriting personal data identifier fields with fake personal data. Substitution anonymization involves either swapping in customised made-up data from a table, or by using an algorithm to generate random data which matches the expected value for the field type.
Figure 2. Example Of Substitution Anonymization Algorithm
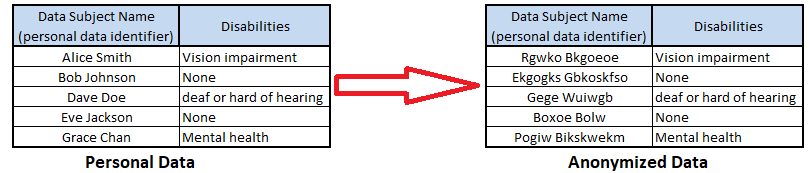
- Pros: The anonymized dataset maintains its structure, therefore is a suitable anonymization technique for creating production quality test data for use within the testing phase of the Software Development Lifecycle (SDLC) and for replicating application issues as part of support.
- Cons: There is potential for direct or indirect personal data identifier fields to be missed and to remain undiscovered within the dataset. As actual personal data within the anonymized dataset can be difficult to observe and verify.
Data scrambling or shuffling is a substitution method where the personal dataset is solely used to swap ‘columns’ of data. In the simple example shown in Figure 3, the surnames have been shuffled to create an anonymized dataset.
Figure 3. Data Shuffling Example

- Pros: The anonymized dataset maintains its structure therefore remains suitable for use as test data.
- Cons: Data shuffling has a considerable de-anonymization risk, given the anonymized dataset could be pieced back together to identify individuals. The shuffling algorithm is also at risk of being deciphered. In the example shown in Figure 3, the anonymized data could be reversed engineered by cross referencing a record’s first name and age fields with a third party dataset, or by deciphering the shuffle algorithm, which is substituting in the surname field which held two records ahead each time.
Pseudonymization is referred to in GDPR Article 4, and is a process that replaces personal data identifiers with realistic fictional data, known as a pseudonym or a token. Unlike anonymization, the pseudonymization of personal data is intended to allow the reidentification of personal data when required. A pseudonym value replaces personal data fields in the application dataset. This data substitution is tracked within a separate lookup table, which then can be used reidentify personal data.
Figure 4. Pseudonymization
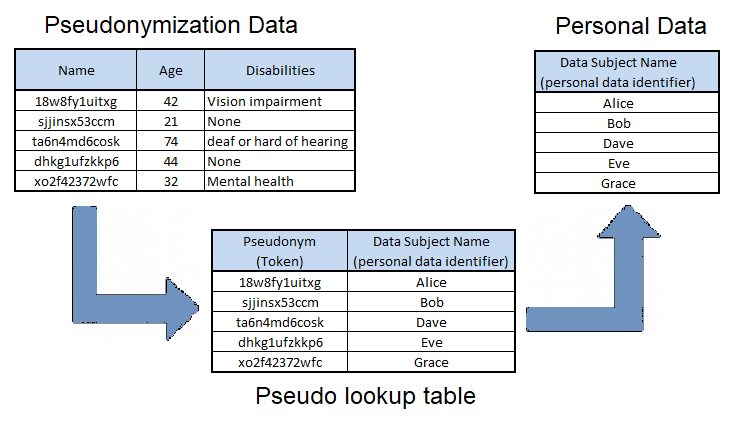
Pseudonymization reduces application privacy risk by moving the personal data identifiers to a separate database server, which is typically isolated from the application’s network environment. If the application dataset holding pseudonymization data is compromised, an attacker or third party does not have the ability to lookup the pseudo value and identify personal data subjects.
Article 4 (5)‘pseudonymisation’ means the processing of personal data in such a manner that the personal data can no longer be attributed to a specific data subject without the use of additional information, provided that such additional information is kept separately and is subject to technical and organisational measures to ensure that the personal data are not attributed to an identified or identifiable natural person.
Pseudonymization is also known as tokenization, and can be configured to provide token data that matches the field type and expected data value, allowing even legacy databases to maintain structure. Tokenization solutions are used by Apple Pay, Samsung Pay and Android Pay to prevent payment card fraud, by storing a token value on each smart phone instead of a payment card number. When a smart phone card payment is requested, the token held on the smart phone is sent and matched to the stored payment card details held within a secured data centre, where the payment is processed. Tokenization solutions have proven popular within the Payment Card Industry (PCI), as they reduce the risk of payment card fraud and data breaches, and substantially lower organizational costs by significantly reducing the number of PCI Data Security Standard requirements an organization has to comply with.
In conclusion, the use of tokenization by applications should be considered as a proven technology to reduce GDPR compliance overheads and cost while mitigating data subject privacy risk, with pseudonymization specifically cited as a risk mitigation option within Article 32 (1).
Article 32 (1)…the controller and the processor shall implement appropriate technical and organisational measures to ensure a level of security appropriate to the risk, including inter alia as appropriate (a) the pseudonymisation and encryption of personal data;
Hashing is a form of pseudonymization that uses a mathematical algorithm to transform personal data fields into fixed length obscure alphanumeric strings, known as hash values or message digests. The hashing of plaintext fields into hash values is intended to be a one way data transformation process, as a hashing algorithm is not reversible; that is, able to transform a hash value back into plaintext. Hashing is typically used by applications to verify plaintext inputs by hashing a plaintext input value using a defined hashing algorithm. the resulting hash value can be checked against a previously calculated and stored hash value. If the hash values are the same, it is extremely likely the plaintext input and previously hashed plaintext are the same. The privacy risk mitigation is that the plaintext values are not held within the dataset.
Applications should use hashing to protect passwords held in databases, storing password hash values instead of plaintext passwords. When a user inputs a plaintext password during the authentication process, the application converts the plaintext password using the defined hashing algorithm to a hash value, and then checks if it matches the password hash held in the database. Should the application database be compromised, although the password hash values are visible and accessible, they cannot be used for account authentication, and it is near impossible to reverse the hash values back into plaintext passwords.
Figure 5. Password Hashing
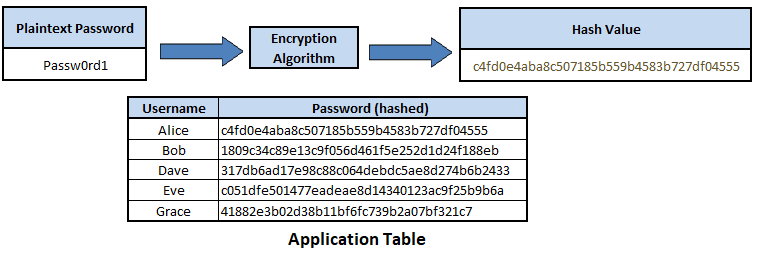
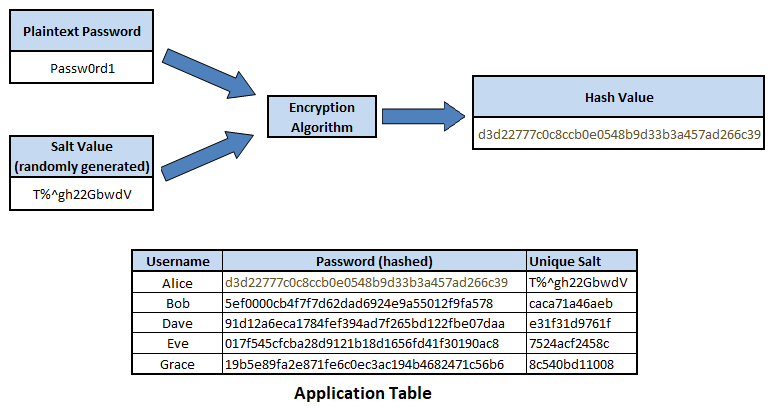
While hashing is intended to be irreversible, it is possible to attempt to crack hash values by using a rainbow table, which is a large pre-computed list of all the possible hash values to plaintext values. However, by ‘salting’ the hashing formula by adding an unique record parameter, and using strong hashing algorithms such as SHA-512, it greatly decreases the likelihood of reverse engineering hash values back into their plaintext value. As given the use of a salt, an attacker would have to pre-compute a unique rainbow table, while the use of a strong hashing algorithm like SHA-512, which uses 512 bits, means it would take an immense amount of computer power and time to create the rainbow table, making the attack method not viable.
Figure 6. Salted Password Hashing
The application’s enforced user password strength is another key element in protecting hashed passwords within compromised datasets. The risk posed by dictionary and brute force attacks, which can use compromised hash values to verify success, can be significantly reduced by enforcing complex user passwords of 8 characters or more.
A complex password strength is considered to include at least one of the following:
- Uppercase letter
- Lowercase letter
- Numerical digit
- Special character (#, $, *, %)
While hashing avoids the management overhead of encryption and can play a role in mitigating privacy risk in protecting passwords, most personal data fields required by applications do not typically suit the hashing pseudonymization approach.
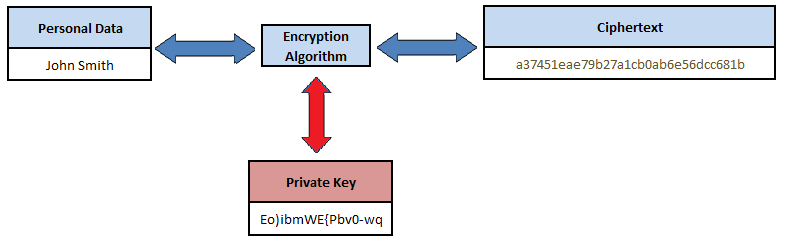
Data encryption uses a mathematical cryptographic algorithm with a secret key code to convert personal data from ‘plaintext’ into ‘ciphertext’ which is unreadable without the knowledge of the secret key to reverse the encryption process, as depicted in Figure 7. Modern cryptographic algorithms are considered to be secure against attack, but the secret or private key is the Achilles Heel with encryption, in that if the key is compromised by an attacker, they would have the ability to decrypt the data.
Figure 7. Symmetric Encryption
There are various software and hardware encryption solutions that can be utilized by applications to encrypt personal data. Encryption can be fully managed by the application, performed directly at the database server, or utilize dedicated encryption management devices known as Hardware Security Modules (HSM). In addition to database encryption, there is filesystem encryption, for protecting personal data within application server temporary files, within audit logs, and within data backups.